Gemini 3.1 Pro vs Claude Sonnet 4.6 vs GPT-5.4|三大AI徹底比較【2026年春】

「ChatGPTがいいの? Claudeがいいの? Geminiもあるけど、結局どれが正解?」──AIツールの導入を検討している方なら、一度はこの疑問にぶつかったことがあるのではないでしょうか。
2026年3月現在、AI市場はGoogle「Gemini 3.1 Pro」、Anthropic「Claude Sonnet 4.6」、OpenAI「GPT-5.4」の三強がしのぎを削る構図になっています。3社ともここ数か月で大型アップデートを重ね、性能差は急速に縮まりつつあります。だからこそ、「自社の業務にはどれが合うのか」を見極めることが、以前にも増して重要になっています。
この記事では、この三大AIを料金・文章力・コーディング・マルチモーダル・安全性・エコシステムの6つの観点で徹底比較します。「とりあえずChatGPTを使っている」方も、「まだどれも試していない」方も、読み終わるころには自社に最適な1つが明確になるはずです。
なお、GPT-5.4の詳細なスペックや活用法については、GPT-5.4完全ガイドで詳しく解説しています。本記事は「3モデル横並びの比較」に特化した内容です。
1. なぜ今「三大AI」を比較すべきなのか
「AIなんてどれも似たようなものでしょ?」と思うかもしれません。たしかに、2024年前半まではそう言える状況でした。しかし2025年後半から2026年にかけて、各社のモデルは明確に「得意分野」が分かれる方向に進化しています。
具体的には、以下の3つの変化が起きています。いわば、AI市場は「三つ巴のオリンピック」に突入した状態です。
- コンテキストウィンドウの大幅拡大:Gemini 3.1 ProとGPT-5.4は100万トークン超のコンテキストに対応。Claude Sonnet 4.6はベータ版で100万トークン、標準でも20万トークンをサポートし、各社ともに大量のデータを一度に処理できるようになっています
- マルチモーダル対応の格差:Geminiは動画・音声をネイティブに処理できる一方、Claudeは画像のみ対応。「何を入力として使えるか」がモデル選定の大きな分かれ目になっています
- 料金体系の多様化:個人向けの月額プランは3社ともほぼ同額(約3,000円)ですが、チーム利用やAPI利用では年間で18万円以上の差がつくケースもあります
つまり、「どれでもいいからAIを使う」時代は終わり、「自社の使い方に合ったAIを選ぶ」ことがコスト面でも成果面でも重要になっているのです。
特に中小企業の場合、限られた予算でAIの効果を最大化するには、最初の選定が肝心です。「どれでもいいから入れてみよう」ではなく、自社の業務特性を理解した上で最適な1つを選ぶことで、投資対効果は何倍にも変わります。
この記事では、技術的な専門知識がなくても判断できるよう、実際のビジネスシーンに基づいた比較を心がけました。最後まで読んでいただければ、「うちの会社にはこれだ」という答えが見つかるはずです。
2. 3モデルの基本プロフィール

Gemini 3.1 Pro ― Googleのマルチモーダル最前線
Gemini 3.1 Proは、2026年2月19日にリリースされたGoogleの最上位AIモデルです。最大の特徴はテキスト・画像・音声・動画・コードすべてをネイティブに処理できるマルチモーダル性能。100万トークンのコンテキストウィンドウ(入力)と最大6.4万トークンの出力に対応し、書籍丸ごと1冊や長時間の会議動画もそのまま入力できます。
ベンチマーク性能も圧倒的で、追跡対象の18項目中12項目で1位を獲得。シンキングモデル機能を搭載しており、複雑な推論タスクにも対応できます。Google Workspaceとの深い統合も強みで、Gmail、Googleドキュメント、スプレッドシートなどとシームレスに連携。すでにGoogleのツールを業務で使っている企業にとっては、追加の導入コストが最も低い選択肢です。
また、API利用料が3社の中で最安(入力$2/100万トークン)という価格優位性も見逃せません。
Claude Sonnet 4.6 ― 推論と安全性の両立
Claude Sonnet 4.6は、2026年2月17日にAnthropicがリリースした最新のSonnetモデルです。最大の特徴は「拡張思考+アダプティブ思考」──通常モードと拡張思考モードを、ユースケースに応じて柔軟に切り替えられます。簡単な質問には即座に回答し、複雑な問題には「じっくり考えてから」答える、という使い分けが1つのモデルで可能です。
コンテキストウィンドウは標準で20万トークン、ベータ版では100万トークンに対応。最大出力は6.4万トークンです。コーディング能力は業界トップクラスで、ソフトウェアの実問題を解くベンチマーク「SWE-bench Verified」で79.6%のスコアを記録しています。Claude Codeでのテストでは、前モデルのSonnet 4.5と比較して70%の開発者がSonnet 4.6を好むという結果が出ています。
安全性への投資も際立っています。有害なリクエストを適切にブロックしつつ、無害なリクエストへの不必要な拒否を前モデルから大幅に削減。「使いにくい」と感じさせない安全設計がなされています。さらに、コンピュータ操作機能にも対応しており、保険業務のベンチマークでは94%の精度を達成しています。
GPT-5.4 ― 最大エコシステムの旗艦モデル
GPT-5.4は、2026年3月5日にリリースされたOpenAIの最新フラッグシップモデルです。105万トークンのコンテキストウィンドウ(入力92.2万トークン+出力12.8万トークン)に対応し、OpenAIとして初の「コンピュータ操作」機能を搭載した汎用モデルとして注目を集めています。
注目すべきはハルシネーション(事実と異なる出力)の大幅削減です。GPT-5.2と比較して虚偽の主張を33%削減しており、業務利用における信頼性が着実に向上しています。GDPvalベンチマークでは83.0%を達成し、専門家レベルの判断に匹敵する性能を示しています。さらに、OSWorldベンチマーク(コンピュータ操作の精度評価)では75.0%を記録し、人間の専門家スコア(72.4%)を上回っています。
最大の強みはエコシステムの圧倒的な広さです。GPTsストア、プラグイン、API連携の数は他社を大きく引き離しており、「やりたいこと」に対応するツールやテンプレートがほぼ確実に見つかります。ChatGPTの月間アクティブユーザー数は3億人を超え、情報やノウハウの蓄積量も圧倒的です。
GPT-5.4の詳しい機能や活用法については、GPT-5.4完全ガイド|ビジネス活用のすべてで解説していますので、あわせてご覧ください。
3. 【一覧表】スペック・料金・機能を横並びで比較
3モデルの主要スペックを一覧表にまとめました。「結局、何が違うの?」という方はまずここをチェックしてください。
| 項目 | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| 開発元 | Google DeepMind | Anthropic | OpenAI |
| リリース | 2026年2月19日 | 2026年2月17日 | 2026年3月5日 |
| コンテキスト | 100万トークン(入力) | 100万トークン(ベータ)/ 20万(標準) | 105万トークン(入力92.2万+出力12.8万) |
| 最大出力 | 6.4万トークン | 6.4万トークン | 12.8万トークン |
| テキスト入力 | 対応 | 対応 | 対応 |
| 画像入力 | 対応 | 対応 | 対応(入力のみ) |
| 音声入力 | 対応(ネイティブ) | 非対応 | 非対応 |
| 動画入力 | 対応(ネイティブ) | 非対応 | 非対応 |
| 推論モード | シンキング対応 | 拡張思考+アダプティブ思考 | 推論レベル調整可 |
| コンピュータ操作 | 非対応 | 対応(精度94%) | 対応(初のOpenAIモデル) |
| API入力単価 | $2.00 / 100万トークン | $3.00 / 100万トークン | $2.50 / 100万トークン |
| API出力単価 | $12.00 / 100万トークン(≤200K) | $15.00 / 100万トークン | $15.00 / 100万トークン |
| 個人プラン月額 | 約3,000円($19.99・Google AI Pro) | 約3,000円($20・Claude Pro) | 約3,000円($20・ChatGPT Plus) |
| 上位プラン月額 | 約37,500円($249.99・Google AI Ultra) | $100〜$200(Claude Max) | 約30,000円($200・ChatGPT Pro) |
| チームプラン月額 | 約3,000円/人($19.99・Google AI Pro per user) | 約3,750円/人($25・年額契約) | 約3,750円/人($25・年額契約) |
※ 為替レートは1ドル=150円で換算(2026年3月時点の概算)。実際の請求額は為替変動により前後します。
表を見ると、API入力単価はGemini 3.1 Proが最安であることがわかります。一方、最大出力トークン数はGPT-5.4が12.8万トークンで最大です。コンテキストウィンドウはGPT-5.4が105万トークンで最大、GeminiとClaude(ベータ)が100万トークンで続きます。マルチモーダル対応ではGeminiが音声・動画のネイティブ処理で大きくリードしており、コンピュータ操作ではClaudeとGPT-5.4の両方が対応しています。
4. 比較1 ― 文章作成・要約力
ビジネスでAIを使う場面として最も多いのが「文章作成」です。メールの下書き、報告書の要約、ブログ記事の作成、プレゼン資料のたたき台──ほぼすべてのビジネスパーソンが恩恵を受ける領域です。
3モデルの文章力を比較すると、以下のような傾向があります。
| 評価軸 | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| 日本語の自然さ | ◎ 非常に自然 | ◎ 非常に自然 | ◎ 非常に自然 |
| 長文の構成力 | ○ 良好 | ◎ 論理的で整然 | ◎ バランスが良い |
| 要約の正確さ | ◎ 長文に特に強い | ○ 良好 | ◎ 的確 |
| クリエイティブ文章 | ○ 無難 | ○ 丁寧で堅実 | ◎ 表現が豊か |
| 指示への忠実さ | ○ おおむね忠実 | ◎ 非常に忠実 | ○ おおむね忠実 |
Claude Sonnet 4.6は「指示に忠実で、論理的に構成された文章」が得意です。たとえば「800文字で、3つのポイントに分けて、初心者にわかるように書いて」と指示した場合、そのとおりの構成で出力してくれる確率が最も高いのはClaude Sonnet 4.6です。社内文書や契約書のドラフトなど、正確さ・誠実さが求められる文章には向いています。アダプティブ思考機能により、文章のトーンや複雑さをタスクに応じて自動調整してくれるのも使いやすいポイントです。
GPT-5.4は「読みやすく、エンゲージメントの高い文章」が得意です。マーケティングコピー、SNS投稿、ニュースレターなど、読者を引きつける文章を書かせるとGPTの表現力が光ります。虚偽の主張がGPT-5.2から33%削減されているため、事実に基づいた文章作成の信頼性も向上しています。
Gemini 3.1 Proは、100万トークンのコンテキストを活かした長文の要約や分析で強みを発揮します。たとえば、100ページの報告書を丸ごと入力して「重要な変更点だけ5つ抜き出して」といった使い方では、Geminiの精度が安定しています。18項目中12項目でベンチマーク1位を獲得している総合力の高さも、文章タスクに反映されています。
もう少し具体的な例を挙げましょう。たとえば「新サービスのプレスリリースを800文字で書いて」と指示した場合、各モデルの出力傾向はこうなります。
- Claude Sonnet 4.6:指定文字数を忠実に守り、事実ベースの落ち着いたトーンで構成。見出し・本文・問い合わせ先まで「テンプレどおり」の整った文章を出力
- GPT-5.4:ややキャッチーな表現を交え、読者の興味を引くリード文を入れてくる傾向。マーケティング寄りの仕上がり
- Gemini 3.1 Pro:Google検索の最新情報を引用して裏付けを入れてくることがある。ファクトベースで堅実な仕上がり
どれが「正解」ということではなく、社風や読者層に合ったトーンを出せるモデルを選ぶのがポイントです。堅めの業界(金融・法務・官公庁)ならClaude Sonnet 4.6、消費者向けサービスならGPT-5.4、データドリブンな報告書ならGemini 3.1 Proが馴染みやすいでしょう。
筆者の体感としては、3社とも日本語の品質は十分実用レベルに達しており、「日本語がおかしい」と感じることはほぼありません。差が出るのは「どんなタイプの文章を書かせるか」という用途の違いです。
5. 比較2 ― コーディング・技術タスク
開発チームを抱える企業にとって、AIのコーディング能力は生産性に直結する要素です。
| 評価軸 | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| コード生成の品質 | ◎ 業界トップクラス | ◎ 業界最高水準 | ◎ 非常に高い |
| バグ修正・デバッグ | ◎ 精度高い | ◎ 精度高い | ◎ 精度高い |
| SWE-bench Verified | 80.6% | 79.6% | 57.7%(SWE-bench Pro) |
| 大規模コードベース理解 | ◎ 100万トークン入力 | ◎ 100万トークン(ベータ)/ 20万(標準) | ◎ 92.2万トークン入力 |
| 自律型エージェント | △ 限定的 | ◎ Claude Code | ◎ Codex |
| 対応言語の幅 | ◎ 幅広い | ◎ 幅広い | ◎ 幅広い |
コーディング領域ではGemini 3.1 ProとClaude Sonnet 4.6が僅差でトップを争っています。SWE-bench VerifiedでGemini 3.1 Proは80.6%、Claude Sonnet 4.6は79.6%を記録しており、いずれも非常に高い水準です。SWE-bench Verifiedとは、GitHubの実際のIssue(バグ報告や機能要望)をAIに渡して、正しくコードを修正できるかを測るベンチマークです。たとえるなら、「実際の患者を診察して正しい治療を行えるか」を測る臨床試験のようなものです。つまり、「おもちゃの問題」ではなく現実のソフトウェア開発で使えるかどうかを直接評価しています。
Gemini 3.1 ProはさらにARC-AGI-2ベンチマークで77.1%を達成しており、汎用的な推論能力の高さも証明しています。コーディングだけでなく、複雑なロジックの設計や問題分析にも強みを発揮します。
特筆すべきはClaude Codeの存在です。Claude Codeは、ターミナルから直接Claudeにコーディングタスクを指示できるCLIツールで、ファイルの読み書き、テストの実行、Git操作までを自律的にこなします。「バグを見つけて直して」と一言指示するだけで、コードベースを分析し、修正し、テストを通すところまで自動で実行してくれます。Claude Codeでのテストでは、開発者の70%がSonnet 4.6をSonnet 4.5より好むという結果も出ています。詳しくはClaude Code完全ガイドをご覧ください。
一方、GPT-5.4もCodexとの連携で強力な自律型コーディングを実現しています。GitHubのIssueをCodexに割り当てると、クラウド上のサンドボックスでコードを書き、プルリクエストまで自動作成してくれます。GPT-5.4はOpenAI初のコンピュータ操作機能も搭載しており、OSWorldベンチマークでは75.0%を記録して人間の専門家(72.4%)を上回る精度でブラウザやアプリケーションを操作できます。
Gemini 3.1 Proは、100万トークンのコンテキストを活かした大規模コードベースの一括分析に強みがあります。「リポジトリ全体を読み込ませて、アーキテクチャの問題点を指摘してもらう」といった使い方では、コンテキストの広さが活きます。ベンチマーク総合力の高さから、コード生成の品質そのものも大幅に向上しています。
AIコーディングツールの比較については、Claude Code vs Cursor vs GitHub Copilot 徹底比較も参考になります。
6. 比較3 ― マルチモーダル(画像・音声・動画)
マルチモーダル対応──つまり「テキスト以外の情報を扱えるか」は、AIの活用範囲を大きく左右する要素です。人間に例えると、テキストだけのAIは「目と耳を塞いで本だけ読んでいる人」のようなもの。画像・音声・動画も扱えるAIは、五感をフル活用できる人に相当します。
| 機能 | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| 画像の理解・分析 | ◎ | ◎ | ◎(入力のみ) |
| PDF・文書の解析 | ◎ | ◎ | ◎ |
| 音声の認識・分析 | ◎ ネイティブ対応 | ✕ 非対応 | △ Whisper連携 |
| 動画の理解・要約 | ◎ ネイティブ対応 | ✕ 非対応 | ✕ 非対応 |
| 画像の生成 | ◎ Imagen 3 | ✕ 非対応 | ◎ DALL-E 3 |
| コンピュータ操作 | ✕ 非対応 | ◎ 精度94% | ◎ OSWorld 75.0% |
マルチモーダル領域ではGemini 3.1 Proが圧倒的にリードしています。テキスト・画像・音声・動画・コードのすべてをネイティブに処理できるのはGeminiだけです。たとえば、1時間の会議録画をそのままGeminiに入力して「議事録を作成して」と指示することが可能です。
具体的なビジネスシーンでの活用例を挙げてみましょう。
- 営業部門:商談の録音を入力して議事録と次のアクションリストを自動生成
- 製造業:製品写真から不具合を検出し、カテゴリ別にレポートを作成
- 研修・教育:研修動画の内容を要約し、確認テストを自動生成
画像の理解・分析に関しては3社とも高い精度を持っています。グラフの読み取り、写真の内容説明、OCR(文字認識)など、基本的な画像タスクはどのモデルでも十分対応可能です。
一方、コンピュータ操作という新しい領域ではClaude Sonnet 4.6とGPT-5.4が対応しています。Claude Sonnet 4.6は保険業務のベンチマークで94%の精度を達成しており、GPT-5.4はOSWorldベンチマークで75.0%(人間の専門家72.4%を上回る)を記録しています。Gemini 3.1 Proはコンピュータ操作には対応していません。
Claude Sonnet 4.6はマルチモーダルの対応範囲こそ限定的ですが、対応している領域(画像・PDF)での分析精度は非常に高く、「画像内のテキストを正確に読み取る」「複雑な図表の内容を正しく解釈する」といったタスクでは安定した結果を返します。
画像生成に関しては、GeminiはImagen 3、GPT-5.4はDALL-E 3を統合しており、テキストから画像を生成できます。Claude Sonnet 4.6には画像生成機能がないため、画像生成が必要な業務では他のツールとの組み合わせが必要です。
マルチモーダルの選び方をシンプルにまとめると、以下のとおりです。
- 動画・音声をAIで処理したい → Gemini 3.1 Pro一択
- コンピュータ操作をAIに任せたい → Claude Sonnet 4.6またはGPT-5.4
- 画像認識+テキスト分析が中心 → 3社とも対応可能。他の評価軸で選んでOK
- 画像生成もAI内で完結させたい → GPT-5.4またはGemini 3.1 Pro
7. 比較4 ― 業務ツール連携・エコシステム
AIの性能がいくら高くても、既存の業務ツールとつながらなければ活用は限定的です。ここでは「どれだけスムーズに業務フローに組み込めるか」を比較します。
| 連携・エコシステム | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| オフィスツール | Google Workspace統合 | 限定的 | Microsoft 365 Copilot |
| サードパーティ連携 | ○ 増加中 | ○ MCP対応 | ◎ GPTs・プラグイン多数 |
| カスタムアプリ構築 | Vertex AI / AI Studio | API / Claude Code | GPTs / Assistants API |
| ノーコード連携 | ○ Zapier等 | ○ Zapier等 | ◎ GPTs + Zapier + Make |
| コミュニティの規模 | ○ 大きい | ○ 成長中 | ◎ 圧倒的に最大 |
GPT-5.4のエコシステムは現時点で他を大きく引き離しています。GPTsストアはちょうどスマートフォンのApp Storeのようなもので、数万のカスタムGPTが公開されており、「採用面接の質問を作りたい」「インボイス制度に対応した請求書を作りたい」など、ニッチな業務向けのテンプレートがすでに用意されています。プログラミングの知識がなくても、GPTsを使えば自社専用のAIアシスタントを作れるのも大きな魅力です。
Gemini 3.1 Proは、Google Workspaceとの統合が最大の武器です。Gmailの返信案を自動生成、スプレッドシートのデータ分析、ドキュメントの要約など、普段使いのGoogleツールの中でAIが動く体験は非常にスムーズです。Google Workspace自体が全世界で30億人以上のユーザーを抱えるプラットフォームであることを考えると、追加コストなしでAIを導入できる企業も多いはずです。
Claude Sonnet 4.6はエコシステムの規模では他社に劣りますが、MCP(Model Context Protocol)という独自のオープンプロトコルを推進しています。MCPを使えば、Claudeを外部のデータソースやツールと柔軟に接続でき、たとえば社内のデータベースやSlack、GitHubなどと直接つなぐことが可能です。Claude Coworkではパソコン操作をAIに丸ごと任せることもできるようになっています。コンピュータ操作機能(精度94%)と組み合わせれば、ブラウザでの作業やアプリケーション操作もAIに委任できるのはClaudeならではの強みです。
8. 比較5 ― 安全性・ハルシネーション・信頼性
AIを業務で使う上で避けて通れないのが「安全性」の問題です。ハルシネーション(もっともらしいウソ)、機密情報の漏洩リスク、有害コンテンツの生成──これらにどう対処しているかはモデル選定の重要な判断材料です。イメージとしては、AIの安全性は車のブレーキのようなもので、性能が高くても止まれなければ使い物になりません。
| 安全性・信頼性 | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| ハルシネーション抑制 | ○ 改善傾向 | ◎ 「わからない」と認める傾向が強い | ◎ GPT-5.2比33%削減 |
| 有害出力の防止 | ○ 標準的 | ◎ 業界最高水準 | ○ 標準的 |
| データプライバシー | 企業向け:学習に不使用 | API:学習に不使用 | API:学習に不使用 |
| 第三者監査・認証 | ○ SOC2対応 | ◎ SOC2 + 独自安全性研究 | ○ SOC2対応 |
| 専門家レベルの判断 | ○ 高水準 | ○ 高水準 | ◎ GDPval 83.0% |
安全性で業界をリードしているのはClaude Sonnet 4.6です。Anthropicは「Constitutional AI」というアプローチで、AIの安全性研究を事業の根幹に据えています。実際の使用感として、Claudeは「知らないことは知らない」と素直に認める傾向が他のモデルより強く、ハルシネーションのリスクが相対的に低いと感じます。
一方、GPT-5.4もハルシネーション対策で大きく前進しています。GPT-5.2と比較して虚偽の主張を33%削減しており、GDPvalベンチマークでは83.0%を達成。これは専門家(プロフェッショナル)のレベルに匹敵するスコアです。事実に基づいた回答の信頼性が着実に向上しています。
Claude Sonnet 4.6では、有害なリクエストを適切にブロックしつつ、無害なリクエストへの不必要な拒否を前モデルから大幅に削減しています。以前のClaudeは「安全すぎて使いにくい」という声もありましたが、Sonnet 4.6では「安全だけど実用的」なバランスに大きく改善されています。
ハルシネーションの具体例を挙げると、たとえば「○○法の第△条の内容を教えて」と質問した場合、存在しない条文をもっともらしく出力してしまうケースがあります。これはどのAIでも起こりうるリスクですが、Claudeは「その条文について確信が持てないため、原文を直接確認することをおすすめします」と正直に伝えてくる頻度が他モデルより高い傾向があります。業務上の意思決定にAIの出力を使う場合、この「自信がないときに正直に言ってくれる」性質は非常に重要です。
もちろん、3社とも安全性への投資は年々強化しており、どのモデルも業務利用に耐えるレベルに達しています。ただし、AI全般に言えることとして、機密情報をそのままプロンプトに入力するのは避けるべきです。API利用であれば学習データに使われないことが各社とも明言されていますが、無料プランやウェブ版ではポリシーが異なる場合があります。自社のデータ管理ポリシーと照らし合わせて確認しましょう。

9. 【ユースケース別】あなたの会社に合うAIはこれだ
ここまでの比較を踏まえて、「結局うちの会社にはどれがいいの?」という疑問に、部門別に答えます。
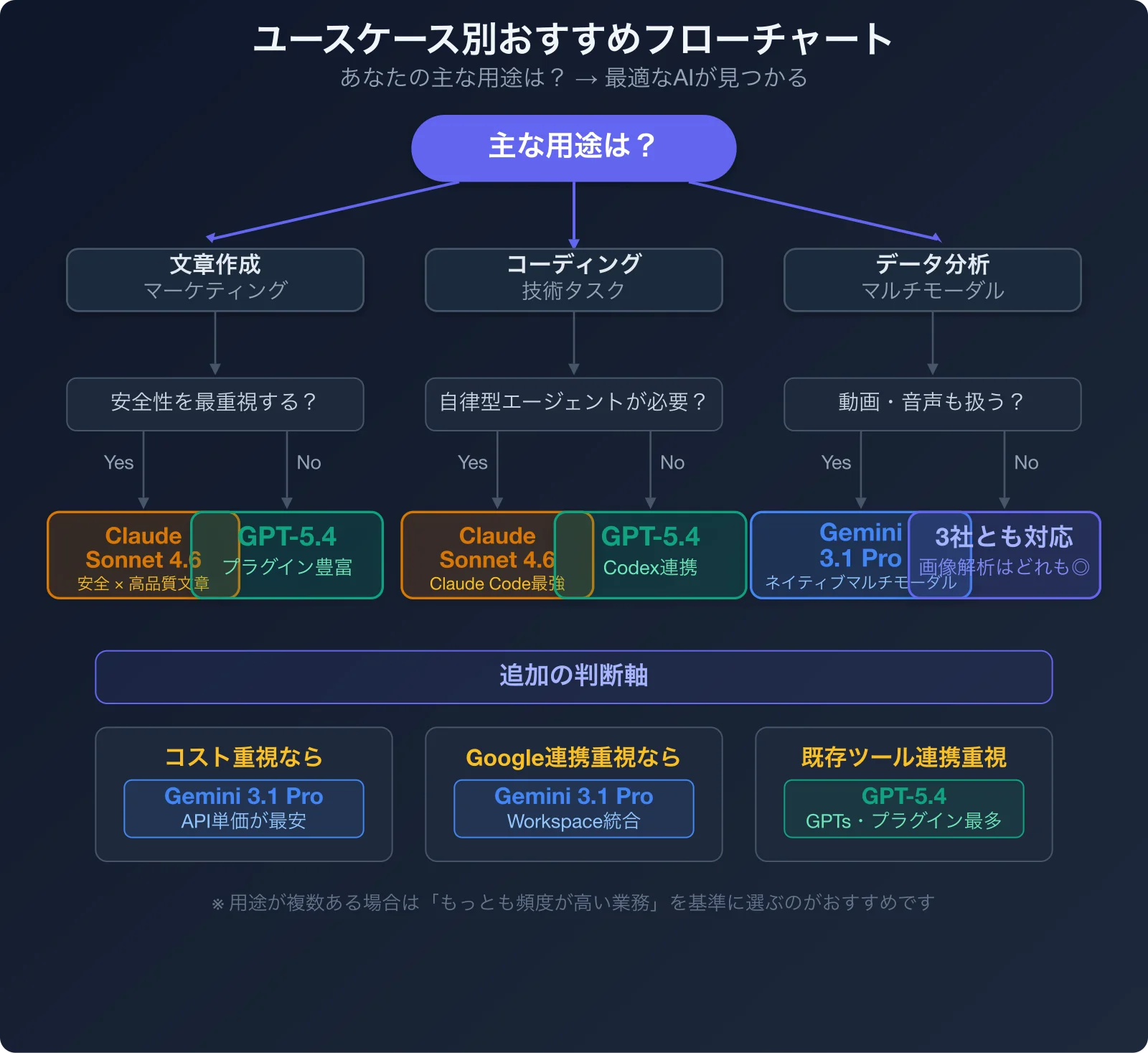
営業・マーケティング部門
おすすめ:GPT-5.4
営業・マーケティングでは「相手に刺さるコンテンツを素早く大量に作る」ことが求められます。GPT-5.4はキャッチコピー、メール文案、SNS投稿、プレゼン資料など、クリエイティブな文章生成に強みがあります。
GPTsストアには営業メールテンプレート、セールスコピー生成、市場調査アシスタントなど多数の専用ツールが揃っており、非エンジニアでもすぐに業務に組み込めるのが最大の利点です。DALL-E 3による画像生成もできるため、プレゼン資料やSNS投稿用の画像もAI内で完結します。さらに、虚偽の主張が33%削減されているため、マーケティング資料のファクトチェックの手間も軽減されます。
ただし、会議の録音からの議事録作成が多い場合はGemini 3.1 Proも有力候補です。音声のネイティブ処理により、録音ファイルをそのまま入力して正確な議事録を生成できます。
バックオフィス(経理・人事・法務)
おすすめ:Claude Sonnet 4.6
経理・人事・法務の業務は「正確さ」と「安全性」が最優先です。契約書のレビュー、就業規則の確認、経費精算ルールの整理──これらの業務でハルシネーションが起きると、深刻な問題につながりかねません。
Claude Sonnet 4.6は、事実に基づかない情報を自信満々に出力するリスクが相対的に低く、「わからないことはわからない」と答える傾向があるため、バックオフィス業務との相性が最も良いモデルです。指示への忠実度が高いので、「以下の契約書から、甲が不利になる条項を3つ抽出して」といった具体的な指示を正確にこなします。コンピュータ操作機能(精度94%)を活用すれば、定型的なPC作業の自動化も可能です。
Googleスプレッドシートでの経費管理が中心の場合はGemini 3.1 Proも検討に値します。Workspace統合により、スプレッドシート上で直接AIに分析を指示できます。
開発・技術チーム
おすすめ:Claude Sonnet 4.6
開発チームにとっては、コーディング能力と自律型エージェントが選定の鍵です。Claude Sonnet 4.6はSWE-bench Verifiedで79.6%の高スコアを記録しており、Claude Codeを使えば「Issueを渡すだけでコードを書いてPRを出してくれる」ワークフローが構築できます。開発者の70%がSonnet 4.5よりSonnet 4.6を好むという結果も、実際の開発現場での使い勝手の良さを裏付けています。
ただし、Gemini 3.1 ProもSWE-bench Verifiedで80.6%を記録しており、コーディング能力は非常に拮抗しています。大規模なレガシーコードベースを扱うチームでは、100万トークンのコンテキストを持つGemini 3.1 ProやGPT-5.4のほうが、コードベース全体を一度に読み込めるメリットがあります。
AIコーディングツールの詳しい比較はClaude Code vs Cursor vs GitHub Copilot 徹底比較で解説しています。
経営企画・戦略部門
おすすめ:Gemini 3.1 Pro
経営企画では「大量の情報を整理し、意思決定に必要なインサイトを抽出する」ことが求められます。100万トークンのコンテキストを持つGemini 3.1 Proなら、数百ページの市場レポート、競合分析資料、財務データを一括で入力し、横断的な分析を指示できます。18項目中12項目でベンチマーク1位という総合力も、多角的な経営分析にとって心強い材料です。
さらに、動画のネイティブ処理を活用すれば、競合のプレゼン動画や業界カンファレンスの講演を入力して「重要なトレンドを10個抽出して」といった指示も可能です。Google Workspaceとの統合により、分析結果をそのままドキュメントやスライドに反映できる点も、経営企画の業務フローにフィットします。
もちろん、AIだけで経営判断を下すのは危険です。AIの出力はあくまで「たたき台」であり、最終的な判断は人間が行うべきです。ただし、「たたき台の質」が上がるだけで、意思決定のスピードは格段に向上します。
たとえば、新規事業の市場調査を外部コンサルに依頼すれば数百万円、社内で手作業なら2〜3週間かかるところ、Geminiに関連資料を一括入力すれば数時間で初期分析のドラフトが得られます。もちろんAIの分析をそのまま鵜呑みにするわけにはいきませんが、「仮説の土台」を素早く作れるだけで、戦略立案のサイクルが大幅に短縮されます。
10. 筆者の本音 ― 1つだけ選ぶなら?
ここまで客観的な比較を続けてきましたが、「で、あなたはどれを使ってるの?」という声が聞こえてきそうなので、筆者の本音をお伝えします。
1つだけ選ぶなら、Claude Sonnet 4.6です。
理由は3つあります。
- 出力の「質」が安定している:文章作成でもコーディングでも、「指示どおりの品質で、毎回安定して出力してくれる」信頼感がClaude Sonnet 4.6にはあります。拡張思考+アダプティブ思考により、タスクの複雑さに応じて自動で推論の深さを調整してくれるのも大きいです。他のモデルだと「今回は良かったけど、次はイマイチ」というブレを感じることがあります
- 安全性を犠牲にしていない:業務で使う以上、ハルシネーションや不適切な出力のリスクは常に気になります。Claudeの「知らないことは知らないと言う」姿勢は、ビジネスでの利用において大きな安心材料です
- Claude Codeの生産性が圧倒的:筆者は日常的にClaude Codeを使ってコーディングしていますが、体感としてひとりAIチームとして十分機能するレベルに達しています。開発者の70%がSonnet 4.5よりSonnet 4.6を好むという結果も、日々の実感と一致します
ただし、これはあくまで「筆者の使い方」に最適化した答えです。
たとえば、Google Workspaceが業務基盤の企業なら、追加コストなしでAIを組み込めるGemini 3.1 Proのほうが合理的です。ベンチマーク18項目中12項目で1位という総合力も魅力的です。マーケティング中心の業務で、クリエイティブな文章や画像生成が多いならGPT-5.4が向いています。動画や音声を多用する業務なら、Gemini一択と言っても過言ではありません。
補足しておくと、2つのAIを併用するという選択肢もあります。筆者の場合、日常的な文章作成やコーディングにはClaude Sonnet 4.6、長時間の動画要約やGoogle Workspace連携にはGemini 3.1 Proと使い分けています。月額6,000円程度で2つのAIの強みをカバーできるので、予算に余裕がある場合は検討の価値があります。
大切なのは「最強のAI」を追い求めることではなく、「自社の業務に最もフィットするAI」を選ぶことです。次のセクションでは、そのための具体的なコストシミュレーションを紹介します。
11. 導入コストシミュレーション ― 月額いくらかかる?
「性能はわかった。で、いくらかかるの?」──経営者にとっては、ここが最大の関心事ですよね。チーム規模別にシミュレーションしてみましょう。
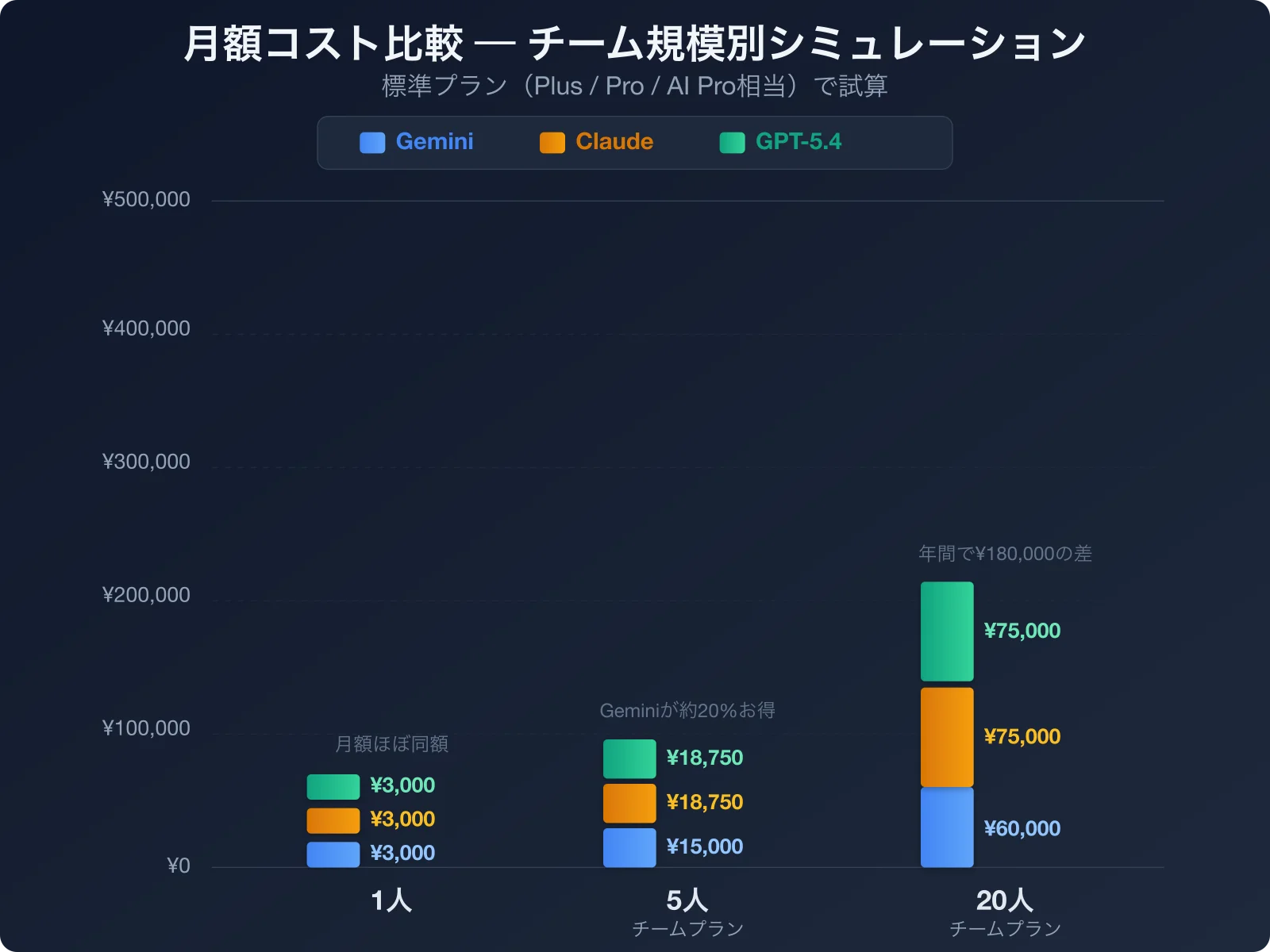
パターン1:経営者1人で使う場合
| サービス | プラン | 月額(税抜概算) |
|---|---|---|
| Gemini(Google AI Pro) | 個人 | 約3,000円 |
| Claude Pro | 個人 | 約3,000円 |
| ChatGPT Plus | 個人 | 約3,000円 |
1人利用なら3社ともほぼ同額です。月額約3,000円で最先端のAIを使えるのは、正直言って破格です。この価格帯なら「どれか1つ試してみて、合わなかったら乗り換える」というアプローチで全く問題ありません。
パターン2:5人チームで使う場合
| サービス | プラン | 月額(税抜概算) | 年額 |
|---|---|---|---|
| Gemini(Google AI Pro per user) | チーム | 約15,000円 | 約180,000円 |
| Claude Team | チーム(年額契約) | 約18,750円 | 約225,000円 |
| ChatGPT Team | チーム(年額契約) | 約18,750円 | 約225,000円 |
5人規模になると差が出始めます。Geminiが年間で約45,000円お得です。すでにGoogle Workspaceを使っている企業なら、Geminiの追加が最もコスト効率が高い選択です。
パターン3:20人部門で使う場合
| サービス | プラン | 月額(税抜概算) | 年額 |
|---|---|---|---|
| Gemini(Google AI Pro per user) | チーム | 約60,000円 | 約720,000円 |
| Claude Team | チーム(年額契約) | 約75,000円 | 約900,000円 |
| ChatGPT Team | チーム(年額契約) | 約75,000円 | 約900,000円 |
20人規模では年間で約180,000円の差が出ます。これは無視できない金額です。ただし、コストだけで判断するのは危険です。「Geminiのほうが安いからGeminiにしよう」と決めた結果、業務に合わず使われなくなるケースは少なくありません。「安くて使われないAI」より「多少高くても毎日使われるAI」のほうが、投資対効果は圧倒的に高くなります。
コスト判断のもう1つのポイントは「AI導入で削減できるコスト」との比較です。たとえば、Claude Teamを5人で導入して月額18,750円かかるとしても、メール返信、議事録作成、資料のたたき台作成などの業務が1人あたり月10時間短縮できれば、時給2,000円換算で月100,000円分の工数削減になります。投資額の5倍以上のリターンです。
もちろんこの計算はあくまで試算ですが、「月額コストの安さ」だけを見て選ぶのではなく、「生産性向上によるリターン」も含めて判断することが重要です。業務との相性が良いモデルを選べば、コスト差以上の価値を生み出せます。
なお、もっと踏み込んだコスト最適化の考え方は「ひとりAIチーム」の作り方の記事で詳しく解説しています。
12. 失敗しないAI選定の3ステップ
「で、結局どうすればいいの?」という方のために、AI選定の具体的な手順を3ステップにまとめました。
ステップ1:「最も頻度の高い業務」を特定する
AIを使いたい業務をすべて書き出し、最も頻繁に行う業務を1つ選んでください。「メールの返信」「議事録の作成」「コードレビュー」「データの集計」など、具体的であるほど良いです。この業務にフィットするモデルを最優先で選びましょう。
ステップ2:無料枠・トライアルで「体感」する
3社とも無料で試せる枠があります。ステップ1で特定した業務を、実際に各モデルで試してみてください。スペック表の比較よりも、「使ってみた感触」のほうがはるかに信頼できる判断材料です。
- Gemini:Google AI Studioで無料利用可能
- Claude:claude.aiで無料プラン利用可能
- ChatGPT:chatgpt.comで無料プラン利用可能
各モデルに同じ質問・同じタスクを投げて、出力の品質を比較するのがポイントです。特に「日本語の自然さ」と「指示の理解度」は、実際に試さないとわかりません。
ステップ3:1か月使って「定着するか」を見る
トライアルで最も良かったモデルの有料プラン(月額約3,000円)に1か月だけ加入してください。この1か月で確認すべきは「毎日使い続けているか」です。
性能がどんなに高くても、操作感が合わなかったり、業務フローにうまく組み込めなかったりすると、自然と使わなくなります。1か月後に「もう手放せない」と感じたら、そのモデルが正解です。「あまり使ってなかった」なら、2番目に良かったモデルに切り替えましょう。
大切なのは「完璧なAIを見つけること」ではなく「使い続けられるAIを見つけること」です。AIは使えば使うほど「効果的なプロンプトの出し方」が身につき、生産性が加速度的に上がっていきます。最初の1か月の体験が、その後の1年を左右すると言っても過言ではありません。
また、社内で「AIチャンピオン」を1人決めるのも効果的です。最初に1人がAIを使いこなし、成功体験を社内に共有することで、「自分もやってみよう」という雰囲気が自然に広がります。いきなり全社導入を狙うより、まずは1人の成功事例を作ることをおすすめします。
13. まとめ
三大AI──Gemini 3.1 Pro、Claude Sonnet 4.6、GPT-5.4を6つの観点で比較してきました。最後に、各モデルの「こんな会社におすすめ」を整理します。
Gemini 3.1 Pro
こんな会社におすすめ:
- Google Workspaceが業務基盤
- 動画・音声データを多く扱う
- コストを最小限に抑えたい
- 経営企画・データ分析がメイン用途
Claude Sonnet 4.6
こんな会社におすすめ:
- 正確さ・安全性が最優先
- 開発チームの生産性を上げたい
- 契約書・社内文書の作成が多い
- PC操作の自動化にも取り組みたい
GPT-5.4
こんな会社におすすめ:
- 非エンジニアでもすぐ使いたい
- マーケティング・営業がメイン
- 既存ツールとの連携を重視
- 画像生成もAI内で完結させたい
上の表を見て「全部◎に見える」と感じた方は、正しいです。2026年現在、3社のAIはどれも高い水準にあり、「どれを選んでも大きな失敗にはならない」のが実情です。だからこそ、上の「こんな会社におすすめ」リストを参考に、自社との相性で選んでください。
冒頭でもお伝えしたとおり、3社の性能差は急速に縮まっています。「最強のAI」は存在せず、「自社に最適なAI」があるだけです。
迷ったら、まずは1つ試してみてください。月額3,000円、ランチ2回分の投資で、業務のあり方が変わるかもしれません。その一歩を踏み出すきっかけに、この記事がなれば嬉しく思います。